技术速递|使用 Semantic Kernel 和 Foundry Local 构建企业级本地 RAG 应用
作者:卢建晖 - 微软高级云技术布道师排版:Alan Wang在当今由 AI 驱动的环境中,组织越来越希望在维护数据隐私和降低运营成本的同时,使用大语言模型。Microsoft Foundry Local 是一款免费的工具,允许开发者完全在设备上运行生成式 AI 模型 —— 无需 Azure 订阅,无需网络连接,且数据不会离开你的笔记本或桌面设备。将它与微软的 Semantic Kernel 框架
作者:卢建晖 - 微软高级云技术布道师
排版:Alan Wang
在当今由 AI 驱动的环境中,组织越来越希望在维护数据隐私和降低运营成本的同时,使用大语言模型。Microsoft Foundry Local 是一款免费的工具,允许开发者完全在设备上运行生成式 AI 模型 —— 无需 Azure 订阅,无需网络连接,且数据不会离开你的笔记本或桌面设备。将它与微软的 Semantic Kernel 框架结合,能构建出一个强大的本地 Retrieval-Augmented Generation(RAG)应用。
本文将带你设计与实施一个生产级的 RAG 解决方案,重点关注实践性的实现模式与架构考量。
技术栈理解
Foundry Local:搭载 ONNX Runtime 的 Edge AI
Foundry Local 使 AI 模型推理能够高效、安全、可扩展地在本地设备上执行。它构建在 ONNX Runtime 之上,为企业应用程序提供了几个关键优势:
- 硬件抽象:支持多种执行提供者,如 NVIDIA CUDA、AMD、Qualcomm、Intel,以优化性能。
- 模型灵活性:本地网关实现了与 OpenAI 相同的
/v1/chat/completions路由,因此你可以将现有 Python 或 JS 客户端指向base_url=manager.endpoint,即可无缝工作。 - 隐私优先架构:所有处理全部在本地进行,敏感数据绝不离开设备。
Semantic Kernel:AI 协作层
Semantic Kernel 是一款轻量级的开源开发工具包,可帮助你轻松构建 AI 代理并将最新的 AI 模型集成到 C#、Python 或 Java 代码中。它作为你应用逻辑与 AI 模型之间的中间层,具备以下功能:
- 模型无关设计:可通过最小代码改动在不同的大语言模型之间切换。
- 插件架构:支持通过自定义功能和工具来扩展功能。
- 内存管理:内置语义内存与向量存储支持。
RAG 架构概览
Foundry Local 与 Semantic Kernel 的整合,打造出一个高性能、隐私优先、可扩展的本地 RAG 架构:
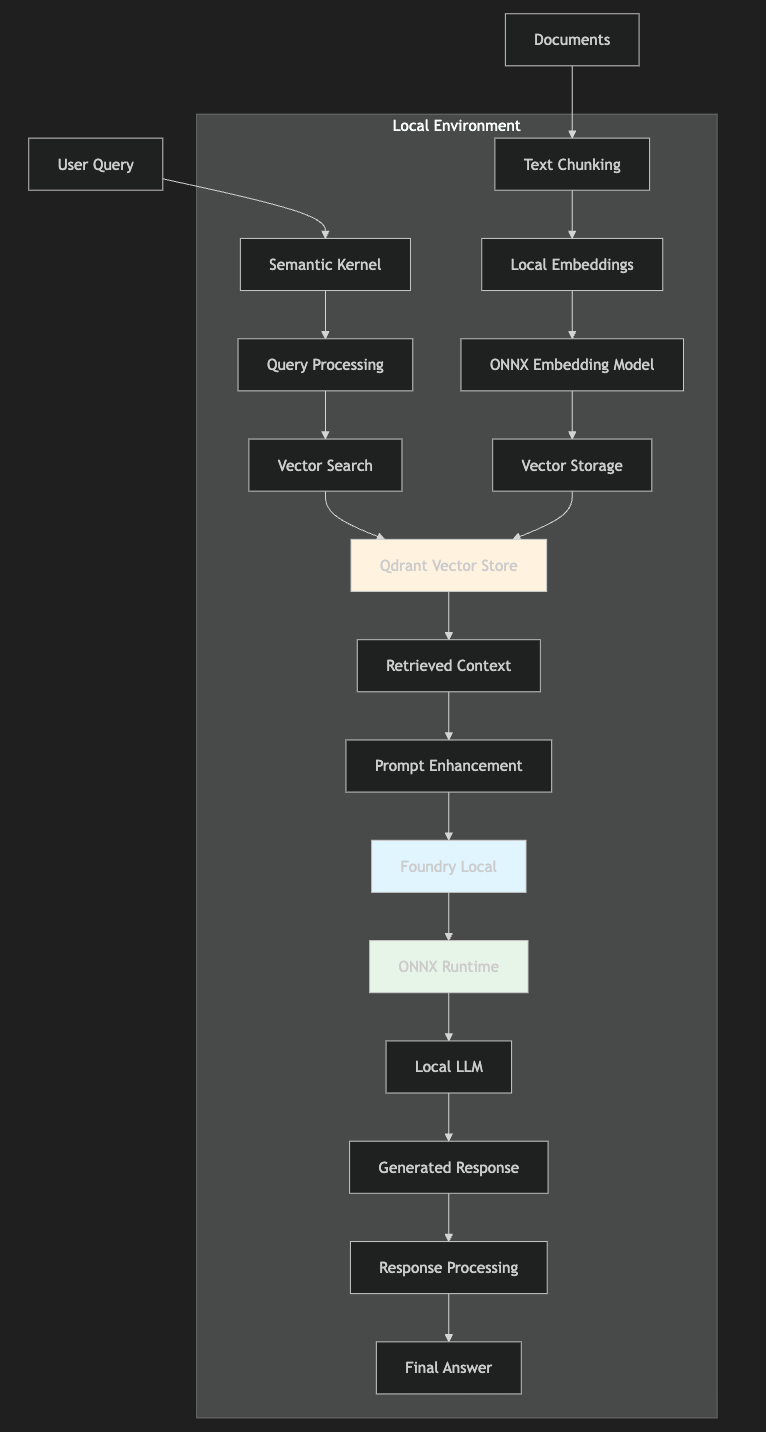
所有组件 —— 从文档处理到响应生成 —— 都在本地环境中独立运作。
实施指南
准备与环境设置
请确认你的开发环境满足以下条件:
- .NET 8.0 或更高版本
- Docker(用于运行 Qdrant 向量存储)
- Qdrant
- 已安装 Foundry Local
- Visual Studio Code + .NET Extension Pack
第一步:安装与设置 Foundry Local
安装并配置 Foundry Local:
# Install Foundry Local (Windows/macOS)
# Windows: Download installer from GitHub releases
# macOS: brew install foundrylocal
# List available models
foundry model list
# Download a suitable model (e.g., Phi-3.5-mini)
foundry model download qwen2.5-0.5b-instruct-generic-cpu
# Start the service
foundry service start Foundry Local 会根据系统硬件与软件配置自动下载最适合的模型版本(例如 NVIDIA GPU 下使用 CUDA 版本的模型)。
第二步:使用 Docker 配置 Qdrant 向量存储
通过 Docker 部署 Qdrant:
# Start Qdrant container
docker run -p 6333:6333 -p 6334:6334 \ -e QDRANT__SERVICE__HTTP_PORT="6333" \ -e QDRANT__SERVICE__GRPC_PORT="6334" \ qdrant/qdrant第三步:使用本地模型配置 Semantic Kernel
在构建完全本地化的 RAG 解决方案时,一个关键挑战是如何处理嵌入。近几个月我们看到的大多数示例都展示了如何通过调用 OpenAI 或 Azure Search 等云服务来实现 RAG。但对于必须确保数据保留在本地的使用场景来说,这种方式可能并不适用。
解决方案是将 Semantic Kernel 配置为同时使用 Foundry Local 来执行聊天补全,以及使用基于 ONNX 的嵌入模型来进行文本向量化。
using Microsoft.SemanticKernel;
using Microsoft.SemanticKernel.Connectors.Onnx;
using Microsoft.SemanticKernel.Memory;
// Initialize the Semantic Kernel builder for local AI orchestration
var builder = Kernel.CreateBuilder();
// Configure Foundry Local chat completion service
// This connects to the local Foundry service running on port 5273
// The service provides OpenAI-compatible API endpoints for seamless integration
builder.AddOpenAIChatCompletion(
modelId: "qwen2.5-0.5b-instruct-generic-gpu", // Model identifier matching Foundry Local
endpoint: new Uri("http://localhost:5273/v1"), // Local Foundry endpoint
apiKey: "", // No API key needed for local service
serviceId: "qwen2.5-0.5b"); // Service identifier for kernel resolution
// Configure local ONNX embedding model for text vectorization
// These models run entirely offline for privacy-preserving embeddings
var embeddingModelPath = "Your Jinaai jina-embeddings-v2-base-en onnx model path";
var vocabPath = "Your Jinaai jina-embeddings-v2-base-en vocab file path";
// Add BERT-based ONNX embedding generation
// This enables local text-to-vector conversion without cloud dependencies
builder.AddBertOnnxTextEmbeddingGeneration(embeddingModelPath, vocabPath);
// Build the configured kernel instance
var kernel = builder.Build();第四步:实现向量存储操作
VectorStoreService 类为在 Qdrant 中管理文档嵌入提供了一个健壮的接口。该服务负责集合初始化、向量存储以及相似度搜索等操作,这些功能构成了我们 RAG 系统的核心基础。
public class VectorStoreService
{
private readonly QdrantClient _client;
private readonly string _collectionName;
/// <summary>
/// Initializes a new instance of the VectorStoreService
/// </summary>
/// <param name="endpoint">Qdrant server endpoint (e.g., http://localhost:6334)</param>
/// <param name="apiKey">API key for authentication (empty for local deployment)</param>
/// <param name="collectionName">Name of the vector collection to manage</param>
public VectorStoreService(string endpoint, string apiKey, string collectionName)
{
_client = new QdrantClient(new Uri(endpoint));
_collectionName = collectionName;
}
/// <summary>
/// Initializes the vector collection with specified dimensions
/// Creates a new collection if it doesn't exist, otherwise uses the existing one
/// </summary>
/// <param name="vectorSize">Embedding vector dimensions (default: 768 for most BERT models)</param>
public async Task InitializeAsync(int vectorSize = 768)
{
try
{
// Attempt to get existing collection info
await _client.GetCollectionInfoAsync(_collectionName);
}
catch
{
// Create new collection with cosine similarity for semantic search
await _client.CreateCollectionAsync(_collectionName, new VectorParams
{
Size = (ulong)vectorSize,
Distance = Distance.Cosine // Cosine similarity works well for text embeddings
});
}
}
/// <summary>
/// Stores or updates a vector embedding with associated metadata
/// </summary>
/// <param name="id">Unique identifier for the vector point</param>
/// <param name="embedding">Vector embedding of the text chunk</param>
/// <param name="metadata">Associated metadata (document ID, chunk text, etc.)</param>
public async Task UpsertAsync(string id, ReadOnlyMemory<float> embedding, Dictionary<string, object> metadata)
{
// Create a point structure for Qdrant storage
var point = new PointStruct
{
Id = new PointId { Uuid = id },
Vectors = embedding.ToArray(),
Payload = { }
};
// Convert metadata to Qdrant-compatible format
foreach (var kvp in metadata)
{
point.Payload[kvp.Key] = kvp.Value switch
{
string s => s,
int i => i,
bool b => b,
_ => kvp.Value.ToString() ?? string.Empty
};
}
// Store the vector point in the collection
await _client.UpsertAsync(_collectionName, new[] { point });
}
/// <summary>
/// Performs similarity search to find relevant document chunks
/// </summary>
/// <param name="queryEmbedding">Vector embedding of the user query</param>
/// <param name="limit">Maximum number of results to return</param>
/// <returns>List of scored points ordered by similarity</returns>
public async Task<List<ScoredPoint>> SearchAsync(ReadOnlyMemory<float> queryEmbedding, int limit = 3)
{
var searchResult = await _client.SearchAsync(_collectionName, queryEmbedding.ToArray(), limit: (ulong)limit);
return searchResult.ToList();
}
}第五步:构建 RAG 查询管道
RagQueryService 负责协调完整的 RAG 工作流,从查询向量化到上下文检索,再到生成响应。该服务展示了将本地嵌入与 Foundry Local 的聊天补全功能相结合所带来的强大能力:
public class RagQueryService
{
private readonly IEmbeddingGenerator<string, Embedding<float>> _embeddingService;
private readonly IChatCompletionService _chatService;
private readonly VectorStoreService _vectorStoreService;
/// <summary>
/// Initializes the RAG query service with required dependencies
/// </summary>
public RagQueryService(
IEmbeddingGenerator<string, Embedding<float>> embeddingService,
IChatCompletionService chatService,
VectorStoreService vectorStoreService)
{
_embeddingService = embeddingService;
_chatService = chatService;
_vectorStoreService = vectorStoreService;
}
/// <summary>
/// Processes a user question through the complete RAG pipeline
/// </summary>
/// <param name="question">User's natural language question</param>
/// <returns>AI-generated answer based on retrieved context</returns>
public async Task<string> QueryAsync(string question)
{
// Step 1: Convert the user question into a vector embedding
// This embedding will be used for similarity search in the vector store
var queryEmbeddingResult = await _embeddingService.GenerateAsync(question);
var queryEmbedding = queryEmbeddingResult.Vector;
// Step 2: Perform semantic search to find the most relevant document chunks
// Retrieve top 5 most similar chunks based on cosine similarity
var searchResults = await _vectorStoreService.SearchAsync(queryEmbedding, limit: 5);
// Step 3: Extract and concatenate text content from search results
// This forms the context that will inform the AI's response
string contextText = "";
foreach (var result in searchResults)
{
if (result.Payload.TryGetValue("text", out var text))
{
contextText += text.ToString() + " ";
}
}
// Step 4: Construct a prompt that combines the question with retrieved context
// This prompt guides the AI to answer based on the specific context
var prompt = $@"Based on the question: '{question}', please provide a comprehensive answer using the following context.
Optimize and simplify the content for clarity:
Context: {contextText}";
// Step 5: Create chat history with system instruction and user prompt
var chatHistory = new ChatHistory();
chatHistory.AddSystemMessage("You are a helpful assistant that answers questions based on the provided context. " +
"Use only the information from the context to answer questions accurately.");
chatHistory.AddUserMessage(prompt);
// Step 6: Generate streaming response using Foundry Local
// Stream the response for better user experience
var fullMessage = string.Empty;
await foreach (var chatUpdate in _chatService.GetStreamingChatMessageContentsAsync(chatHistory, cancellationToken: default))
{
if (chatUpdate.Content is { Length: > 0 })
{
fullMessage += chatUpdate.Content;
}
}
return fullMessage ?? "I couldn't generate a response based on the available context.";
}
}第六步:文档摄取与文本分块
DocumentIngestionService 负责处理 RAG 所需的关键文档预处理任务。它通过带有重叠的智能文本分块来确保上下文的连续性,并生成嵌入以支持高效的语义搜索:
public class DocumentIngestionService
{
private readonly IEmbeddingGenerator<string, Embedding<float>> _embeddingService;
private readonly VectorStoreService _vectorStoreService;
/// <summary>
/// Initializes the document ingestion service
/// </summary>
public DocumentIngestionService(
IEmbeddingGenerator<string, Embedding<float>> embeddingService,
VectorStoreService vectorStoreService)
{
_embeddingService = embeddingService;
_vectorStoreService = vectorStoreService;
}
/// <summary>
/// Processes a document by chunking text and storing embeddings
/// </summary>
/// <param name="documentPath">File path to the document to process</param>
/// <param name="documentId">Unique identifier for tracking the document</param>
public async Task IngestDocumentAsync(string documentPath, string documentId)
{
// Read the entire document content
var content = await File.ReadAllTextAsync(documentPath);
// Split document into manageable chunks with overlap for context preservation
// 300 words per chunk with 60-word overlap ensures semantic continuity
var chunks = ChunkText(content, chunkSize: 300, overlap: 60);
// Process each chunk individually
for (int i = 0; i < chunks.Count; i++)
{
var chunk = chunks[i];
// Generate vector embedding for the text chunk
var embeddingResult = await _embeddingService.GenerateAsync(chunk);
var embedding = embeddingResult.Vector;
// Store the chunk embedding with comprehensive metadata
await _vectorStoreService.UpsertAsync(
id: Guid.NewGuid().ToString(),
embedding: embedding,
metadata: new Dictionary<string, object>
{
["document_id"] = documentId, // Links chunk to original document
["chunk_index"] = i, // Maintains chunk order
["text"] = chunk, // Stores original text for retrieval
["document_path"] = documentPath // Tracks source file location
}
);
}
}
/// <summary>
/// Implements intelligent text chunking with configurable overlap
/// Overlap ensures that context spanning chunk boundaries is preserved
/// </summary>
/// <param name="text">Text content to chunk</param>
/// <param name="chunkSize">Number of words per chunk</param>
/// <param name="overlap">Number of overlapping words between chunks</param>
/// <returns>List of text chunks with preserved context</returns>
private List<string> ChunkText(string text, int chunkSize, int overlap)
{
var chunks = new List<string>();
var words = text.Split(' ', StringSplitOptions.RemoveEmptyEntries);
// Create overlapping chunks to maintain context continuity
for (int i = 0; i < words.Length; i += chunkSize - overlap)
{
// Extract words for this chunk, respecting boundaries
var chunkWords = words.Skip(i).Take(chunkSize).ToArray();
var chunk = string.Join(" ", chunkWords);
chunks.Add(chunk);
// Stop if we've processed all words
if (i + chunkSize >= words.Length)
break;
}
return chunks;
}
}第七步:编排完整的 RAG 应用
最后这一步演示了如何将所有组件组装起来,构建一个可运行的 RAG 应用。代码展示了从服务初始化、文档处理到查询执行的完整工作流程:
// Step 1: Retrieve configured services from the Semantic Kernel
// These services were configured in Step 3 with local models
var chatService = kernel.GetRequiredService<IChatCompletionService>(serviceKey: "qwen2.5-0.5b");
var embeddingService = kernel.GetRequiredService<IEmbeddingGenerator<string, Embedding<float>>>();
// Step 2: Initialize the vector store service
// Connect to local Qdrant instance running on port 6334
// Collection name "demodocs" will store our document embeddings
var vectorStoreService = new VectorStoreService(
endpoint: "http://localhost:6334",
apiKey: "", // No API key needed for local Qdrant
collectionName: "demodocs");
// Step 3: Initialize the vector collection
// This creates the collection if it doesn't exist, with proper embedding dimensions
await vectorStoreService.InitializeAsync();
// Step 4: Create service instances for document processing and querying
var documentIngestionService = new DocumentIngestionService(embeddingService, vectorStoreService);
var ragQueryService = new RagQueryService(embeddingService, chatService, vectorStoreService);
// Step 5: Ingest a sample document into the RAG system
// Replace with your actual document path and provide a unique document ID
var filePath = "./foundry-local-architecture.md";
var documentId = "foundry-architecture-doc";
// Process the document: chunk text, generate embeddings, and store in vector database
await documentIngestionService.IngestDocumentAsync(filePath, documentId);
// Step 6: Test the RAG system with a sample query
var question = "What's Foundry Local?";
// Execute the complete RAG pipeline:
// 1. Convert question to embedding
// 2. Search for relevant document chunks
// 3. Generate contextual response using Foundry Local
var answer = await ragQueryService.QueryAsync(question);
// Step 7: Display the result
Console.WriteLine($"Question: {question}");
Console.WriteLine($"Answer: {answer}");关键集成要点:
- 服务解析:内核会自动解析已配置的聊天和嵌入服务
- 向量存储管理:通过正确初始化来确保集合存在且维度正确
- 错误处理:系统能够优雅地处理集合缺失或连接问题
- 可扩展性:该模式支持多文档及并发查询
结论
使用 Semantic Kernel 和 Foundry Local 构建 RAG 应用,为注重隐私且具成本效益的 AI 解决方案提供了坚实的基础。这种架构使组织能够在完全掌控自身数据与基础设施的前提下,充分利用强大的语言模型能力。
将 Semantic Kernel 的编排能力与 Foundry Local 的边缘优化推理相结合,可以打造一套从开发到企业部署均可扩展的生产级平台。随着本地 AI 生态的不断成熟,这一方法能够帮助组织在满足隐私与安全要求的同时,抢先利用新兴能力。
通过实施本指南中介绍的模式与实践,开发团队可以构建出既符合企业级性能要求,又不牺牲数据隐私与运营成本的高阶 RAG 应用。

微软开发者社区,邀请来自微软以及技术社区专家,带来最前沿的技术干货与实践经验。在这里,您将看到深度教程、最佳实践和创新解决方案。
更多推荐
 29
29 0
0- 0



 已为社区贡献48条内容
已为社区贡献48条内容

所有评论(0)