技术速递|构建双 Sidecar Pod:在 Kubernetes 上将 GitHub Copilot SDK 与 Skill Server 相结合
主容器(Nginx)保持精简与专注 —— 只负责提供 HTML 和代理请求。它对 AI 或技能一无所知。Sidecar 1(Copilot Agent)封装所有 AI 逻辑。它使用 GitHub Copilot SDK,管理会话并生成内容。它与 Pod 其余部分的唯一耦合点是环境变量和共享卷。容器镜像支持跨平台构建 —— Node.js 通过官方二进制安装并自动检测架构,确保同一 Dockerfi
作者:卢建晖 - 微软高级云技术布道师
排版:Alan Wang
如何使用 Kubernetes Sidecar 模式来构建一个云原生 AI 博客生成智能体 —— 一个 Sidecar 用于 GitHub Copilot SDK,另一个用于技能管理。本博客从架构设计选择、实现细节到生产就绪建议,提供了全面分析。
为什么使用 Sidecar 模式?
在 Kubernetes 中,Pod 是最小的可部署单元 —— 一个 Pod 可以包含多个容器,这些容器共享相同的网络命名空间和存储卷。Sidecar 模式是在同一个 Pod 内,将辅助容器与主应用容器并排部署。这些 Sidecar 容器在不修改主容器的情况下扩展或增强其功能。
💡 初学者提示:如果你刚接触 Kubernetes,可以将 Pod 想象为一个共享办公室 —— 房间里的每个人(容器)都有自己的办公桌(进程),但共享同一个网络(IP 地址)、同一个文件柜(存储卷),并且无需离开房间即可相互通信(localhost 通信)。
Sidecar 模式并不是一个新概念。早在 2015 年,Kubernetes 官方博客就在一篇关于 Composite Containers 的文章中描述了这一模式。像 Envoy、Istio 和 Linkerd 这样的服务网格项目广泛使用 Sidecar 容器来实现流量管理、可观测性和安全策略。在 AI 应用领域,我们现在正在探索如何将这一经过验证的模式应用到新的场景中。
为什么这很重要?有三个根本原因:
关注点分离
Pod 中的每个容器都承担一个单一且定义清晰的职责。主应用容器无需了解 AI 内容如何生成或技能如何管理 —— 它只负责提供结果。这种分离允许每个组件独立测试、调试和替换,符合 Unix 的“把一件事做好”的哲学。
在实践中,这意味着:前端团队可以迭代 Nginx 配置而不影响 AI 逻辑;AI 工程师可以升级 Copilot SDK 版本而无需触碰技能管理代码;运维人员可以调整技能配置而无需通知开发团队。
共享 Localhost 网络
Pod 内的所有容器共享相同的网络命名空间,拥有相同的 127.0.0.1。这意味着 Sidecar 之间的通信只是简单的 localhost HTTP 调用 —— 无需服务发现、无需 DNS 解析、无需跨节点网络跳转。
从性能角度看,localhost 通信通过内核的 loopback 接口,延迟通常在微秒级。相比之下,跨 Pod 的 ClusterIP Service 调用需要通过 kube-proxy 的 iptables/IPVS 规则进行路由,延迟通常在毫秒级。对于需要频繁交互的 AI agent 场景,这种差异具有实际意义。
从安全角度看,localhost 通信不会经过任何网络接口,因此天然免疫于集群中其他 Pod 的窃听。除非显式配置 Service,否则 Sidecar 端口不会暴露到 Pod 之外。
通过共享卷实现高效数据传输
Kubernetes 的 emptyDir 卷允许同一 Pod 内的容器共享磁盘文件。一旦某个 Sidecar 写入文件,主容器即可立即读取并提供服务 —— 无需消息队列、无需额外 API 调用、无需数据库。这非常适合一个容器生成工件(例如生成的博客文章),另一个容器消费它们的工作流。
⚠️ 技术精确说明:“高效”在这里意味着消除了网络序列化/反序列化和消息中间件的开销。然而,emptyDir 本质上依赖标准文件系统 I/O(磁盘读写或 tmpfs),并不等同于操作系统级的“零拷贝”(例如 sendfile() 系统调用或 DMA 直接内存访问)。对于博客内容生成这种文件级数据传输场景,文件系统共享已经非常高效且足够简单。
在 gh-cli-blog-agent 项目中,我们将这一模式发挥到极致,在单个 Pod 内使用两个 Sidecar: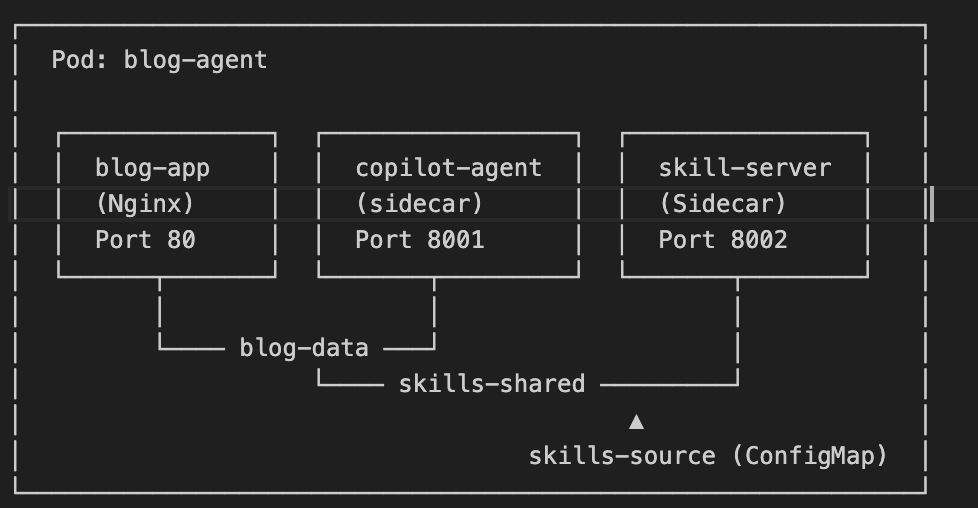
关于 Kubernetes 原生 Sidecar 容器的说明
值得注意的是,Kubernetes 1.28(2023 年 8 月)通过 KEP-753 引入了原生 Sidecar 容器支持,并在 Kubernetes 1.33(2025 年 4 月)达到 GA(正式可用)。原生 Sidecar 通过在 initContainers 上设置 restartPolicy: Always 实现,提供了传统方式所不具备的能力:
-
确定性的启动顺序:init 容器按声明顺序启动,主容器仅在 Sidecar 容器就绪后启动
-
非阻塞 Pod 终止:主容器退出后,Sidecar 会自动清理,防止 Job/CronJob 卡住
-
探针支持:Sidecar 可以配置 startup、readiness 和 liveness 探针以指示运行状态
本项目当前采用传统方式,将 Sidecar 作为常规容器部署,并通过应用级健康检查轮询(wait_for_skill_server)处理启动依赖。这种方式兼容所有 Kubernetes 版本(1.24+),适用于需要广泛兼容性的场景。
如果你的集群版本 ≥ 1.29(或 ≥ 1.33 以获得 GA 稳定性),我们强烈建议迁移到原生 Sidecar,以获得平台级启动顺序保障和更优雅的生命周期管理。迁移示例:
# Native Sidecar syntax (Kubernetes 1.29+)
initContainers:
- name: skill-server
image: blog-agent-skill
restartPolicy: Always # Key: marks this as a Sidecar
ports:
- containerPort: 8002
startupProbe: # Platform-level startup readiness signal
httpGet:
path: /health
port: 8002
periodSeconds: 2
failureThreshold: 30
- name: copilot-agent
image: blog-agent-copilot
restartPolicy: Always
ports:
- containerPort: 8001
containers:
- name: blog-app # Main container starts last; Sidecars are ready
image: blog-agent-main
ports:
- containerPort: 80
架构概览
该部署定义了三个容器和三个卷(Volume):
| 容器 | 镜像 | 端口 | 角色 |
|---|---|---|---|
| blog-app | blog-agent-main | 80 | Nginx —— 提供 Web UI 并反向代理到 Sidecar 容器 |
| copilot-agent | blog-agent-copilot | 8001 | FastAPI —— 基于 GitHub Copilot SDK 的 AI 博客生成服务 |
| skill-server | blog-agent-skill | 8002 | FastAPI —— 技能文件管理与同步服务 |
| 卷名称 | 类型 | 用途 |
|---|---|---|
| blog-data | emptyDir | Copilot agent 写入生成的博客内容,Nginx 负责对外提供访问 |
| skills-shared | emptyDir | Skill server 写入技能文件,Copilot agent 读取这些文件 |
| skills-source | ConfigMap | 由 Kubernetes 管理的技能定义文件(只读) |
💡 设计洞察:三卷设计体现了“最小权限”原则 —— blog-data 仅在 Copilot agent(写)与 Nginx(读)之间共享;skills-shared 仅在 skill server(写)与 Copilot agent(读)之间共享。skills-source 通过 ConfigMap 提供只读技能定义来源,形成单向数据流:ConfigMap → skill-server → shared volume → copilot-agent。
Kubernetes deployment YAML 清晰描述了该结构:
volumes:
- name: blog-data
emptyDir:
sizeLimit: 256Mi # Production best practice: always set sizeLimit to prevent disk exhaustion
- name: skills-shared
emptyDir:
sizeLimit: 64Mi # Skill files are typically small
- name: skills-source
configMap:
name: blog-agent-skill
⚠️ 生产建议:原始配置使用 emptyDir: {} 而未设置 sizeLimit。在生产环境中,无限制的 emptyDir 会无限增长直到耗尽节点磁盘空间,触发节点级 DiskPressure 状态并导致其他 Pod 被驱逐。为 emptyDir 设置合理的 sizeLimit 是 Kubernetes 安全基线的一部分。社区工具如 Kyverno 可以在集群级别强制执行此实践。
Nginx 通过 localhost 将请求反向代理到 Sidecar:
# Reverse proxy to copilot-agent sidecar (localhost:8001 within the same Pod)
location /agent/ {
proxy_pass http://127.0.0.1:8001/;
proxy_set_header Host $host;
proxy_set_header X-Request-ID $request_id; # Enables cross-container request tracing
proxy_read_timeout 600s; # AI generation may take a while
}
# Reverse proxy to skill-server sidecar (localhost:8002 within the same Pod)
location /skill/ {
proxy_pass http://127.0.0.1:8002/;
proxy_set_header Host $host;
}
由于三个容器共享相同的网络命名空间,127.0.0.1:8001 和 127.0.0.1:8002 可直接访问 —— Pod 内通信无需 ClusterIP Service。这是 Kubernetes Pod 网络模型的核心特性:同一 Pod 内的所有容器共享单一网络命名空间,包括 IP 地址和端口空间。
优势一:GitHub Copilot SDK 作为 Sidecar
将 GitHub Copilot SDK 封装为 Sidecar,而不是嵌入主应用,带来了多项架构优势。
理解 GitHub Copilot SDK 架构
在深入之前,先理解 GitHub Copilot SDK 的工作方式。该 SDK 于 2026 年 1 月进入技术预览,将 GitHub Copilot CLI 背后的生产级 agent 运行时以可编程 SDK 形式暴露出来,支持 Python、TypeScript、Go 和 .NET。
SDK 的通信架构如下:
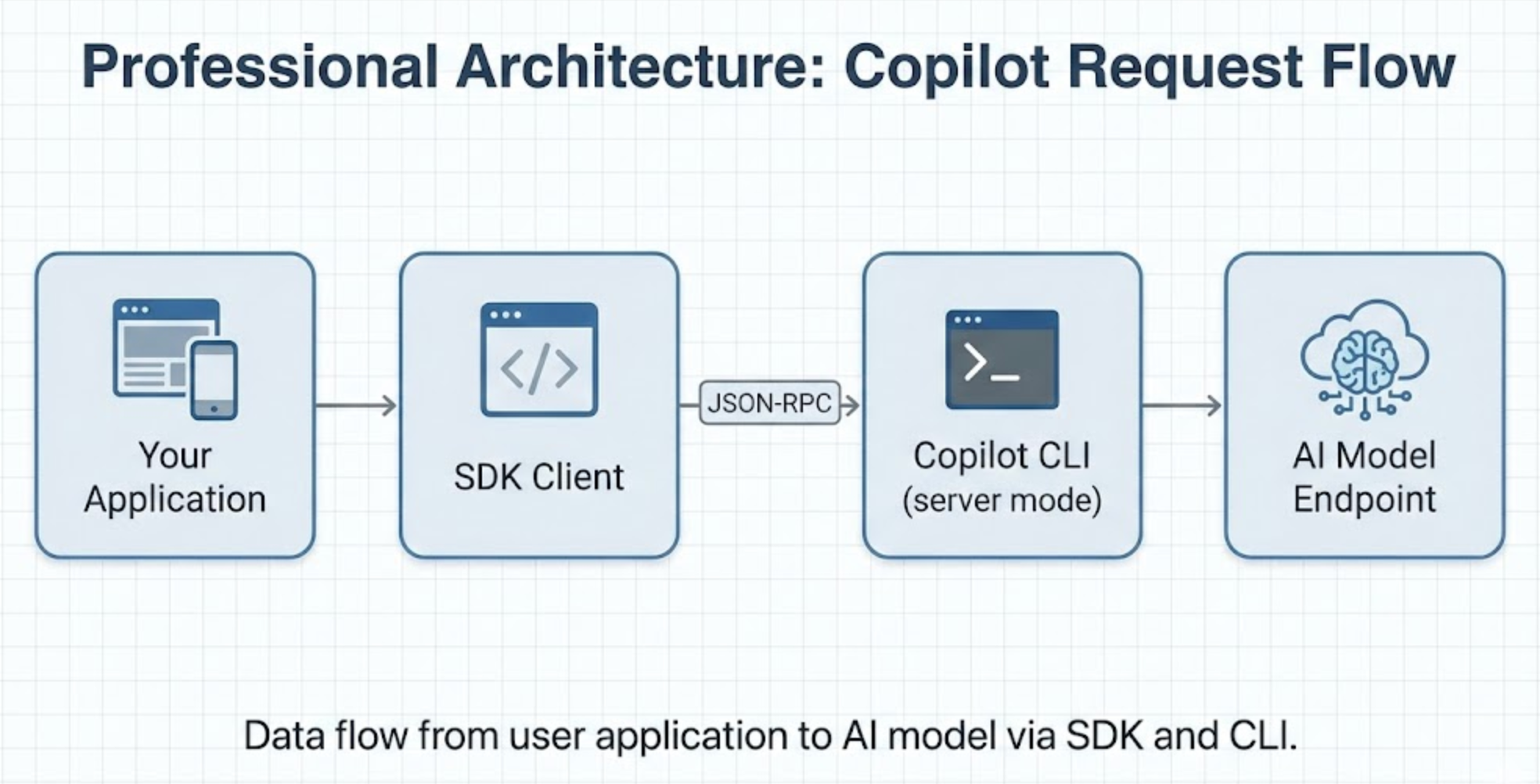
SDK 客户端通过 JSON-RPC 协议与本地运行的 Copilot CLI 进程通信。CLI 负责模型路由、认证管理、MCP server 集成以及其他底层细节。这意味着你无需自行构建 planner、tool loop 和 runtime —— 这些都由一个在 GitHub 规模生产环境中经过验证的引擎提供。
将该 SDK 封装在 Sidecar 容器中的好处是:容器化隔离了 CLI 进程的依赖和运行环境,避免与主应用或其他组件产生依赖冲突。
容器内的跨平台 Node.js 安装
一个值得注意的实现细节是如何在容器中安装 Node.js(Copilot CLI 所需)。Dockerfile 不依赖第三方 APT 仓库(例如 NodeSource —— 在受限网络环境中可能引入 DNS 解析失败和 GPG key 管理问题),而是直接从 nodejs.org 下载官方二进制包,并自动检测架构:
# Install Node.js 20+ (official binary, no NodeSource APT repo needed)
ARG NODE_VERSION=20.20.0
RUN DPKG_ARCH=$(dpkg --print-architecture) \
&& case "${DPKG_ARCH}" in amd64) ARCH=x64;; arm64) ARCH=arm64;; armhf) ARCH=armv7l;; *) ARCH=${DPKG_ARCH};; esac \
&& curl -fsSL "https://nodejs.org/dist/v${NODE_VERSION}/node-v${NODE_VERSION}-linux-${ARCH}.tar.xz" -o node.tar.xz \
&& tar -xJf node.tar.xz -C /usr/local --strip-components=1 --no-same-owner \
&& rm -f node.tar.xz
case 语句将 Debian 架构标识符(amd64、arm64、armhf)映射到 Node.js 命名规范(x64、arm64、armv7l)。这确保同一个 Dockerfile 在 linux/amd64(Intel/AMD)和 linux/arm64(Apple Silicon、AWS Graviton)构建平台上都能无缝运行 —— 随着 ARM 基础设施的广泛采用,这是一个重要考量。
独立生命周期与资源管理
Copilot agent 是资源消耗最大的组件 —— 它需要运行 Copilot CLI 进程、管理 JSON-RPC 通信并处理流式响应。将其隔离在独立容器中,可以为其分配专用 CPU 和内存限制,而不影响轻量级 Nginx 容器:
# copilot-agent: needs more resources for AI inference coordination
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: "1"
memory: 2Gi
# blog-app: lightweight Nginx with minimal resource needs
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 200m
memory: 128Mi
这种资源隔离带来两个关键收益:
-
故障隔离:如果 Copilot agent 因超时或内存峰值(OOMKilled)崩溃,Kubernetes 只会重启该容器 —— Nginx 前端继续运行并提供已生成内容。用户看到的是“生成功能暂时不可用”,而不是“整个站点宕机”。
-
精细化资源调度:Kubernetes 调度器根据 Pod 级资源请求总和选择节点。将资源请求分布在不同容器上,使 kubelet 更精确跟踪各组件实际消耗,有助于 HPA(Horizontal Pod Autoscaler)做出更优扩缩容决策。
优雅的启动协调
在多 Sidecar Pod 中,常规容器会并发启动(注意:这正是前文提到原生 Sidecar 能解决的问题之一)。Copilot agent 通过应用级启动依赖检查来处理 —— 在初始化 CopilotClient 前等待 skill server 健康:
async def wait_for_skill_server(url: str, retries: int = 30, delay: float = 2.0):
"""Wait for the skill-server sidecar to become healthy.
In traditional Sidecar deployments (regular containers), containers start
concurrently with no guaranteed startup order. This function implements
application-level readiness waiting.
If using Kubernetes native Sidecars (initContainers + restartPolicy: Always),
the platform guarantees Sidecars start before main containers,
which can simplify this logic.
"""
async with httpx.AsyncClient() as client:
for i in range(retries):
try:
resp = await client.get(f"{url}/health", timeout=5.0)
if resp.status_code == 200:
logger.info(f"Skill server is healthy at {url}")
return True
except Exception:
pass
logger.info(f"Waiting for skill server... ({i + 1}/{retries})")
await asyncio.sleep(delay)
raise RuntimeError(f"Skill server at {url} did not become healthy")
该模式在传统 Sidecar 架构中至关重要:不能假设启动顺序,因此必须进行显式就绪检查。wait_for_skill_server 函数以 2 秒间隔轮询 http://127.0.0.1:8002/health,最多 30 次(最大等待 60 秒)—— 简单、有效且具备韧性。
💡 对比:使用原生 Sidecar 时,skill-server 会声明为带 startupProbe 的 initContainer。Kubernetes 会确保 skill-server 就绪后再启动 copilot-agent。在这种情况下,wait_for_skill_server 可以简化为单次健康确认,而无需重试循环。
通过环境变量配置 SDK
所有 Copilot SDK 配置均通过 Kubernetes 原生机制传递,体现了 12-Factor App 的“外部化配置”原则:
env:
- name: SKILL_SERVER_URL
value: "http://127.0.0.1:8002"
- name: SKILLS_DIR
value: "/skills-shared/blog/SKILL.md"
- name: COPILOT_GITHUB_TOKEN
valueFrom:
secretKeyRef:
name: blog-agent-secret
key: copilot-github-token
关键设计说明:
-
COPILOT_GITHUB_TOKEN 存储在 Kubernetes Secret 中 —— 绝不写入镜像或作为构建参数传递。使用 GitHub Copilot SDK 需要有效的 GitHub Copilot 订阅(除非使用 BYOK 模式,即 Bring Your Own Key),因此该 token 的安全管理至关重要。
-
SKILLS_DIR 指向由另一个 Sidecar 同步到共享卷中的技能文件。这意味着 Copilot agent 容器镜像是完全无状态的,可在不同技能配置之间复用。
-
SKILL_SERVER_URL 使用 127.0.0.1 而非服务名 —— 因为这是 Pod 内通信,无需 DNS 解析。
🔐 生产安全提示:对于更严格的安全要求,可考虑使用 External Secrets Operator 将 Secrets 从 AWS Secrets Manager、Azure Key Vault 或 HashiCorp Vault 同步,而不是直接在 Kubernetes 中管理。原生 Kubernetes Secrets 默认仅为 Base64 编码,并非静态加密(除非启用 Encryption at Rest)。
CopilotClient 会话与技能集成
Copilot Sidecar 的核心在于如何创建包含技能目录的会话。当收到博客生成请求时,它创建一个可访问技能定义的会话:
session = await copilot_client.create_session({
"model": "claude-sonnet-4-5-20250929",
"streaming": True,
"skill_directories": [SKILLS_DIR]
})
skill_directories 参数指向共享卷上的文件 —— 这些文件由 skill-server sidecar 放置。这是交接点:skill server 管理可用技能,Copilot agent 消费它们。两个容器无需了解彼此内部实现 —— 它们仅通过文件系统这一隐式契约进行耦合。
💡 关于 Copilot SDK Skills:GitHub Copilot SDK 允许定义自定义 Agents、Skills 和 Tools。Skills 本质上是以 Markdown 格式编写的指令集(通常命名为 SKILL.md),用于定义 agent 在特定领域中的行为、约束和工作流。这与 GitHub Copilot CLI 中的 .copilot_skills/ 目录机制一致。
基于文件的输出到共享卷
生成的博客文章写入 blog-data 共享卷,该卷同时挂载到 Nginx 容器:
BLOG_DIR = os.path.join(WORK_DIR, "blog")
# ...
# Blog saved as blog-YYYY-MM-DD.md
# Nginx can serve it immediately from /blog/ without any restart
Nginx 配置对该目录启用自动索引:
location /blog/ {
alias /usr/share/nginx/html/blog/;
autoindex on;
}
Copilot agent 写入文件的瞬间,即可通过 Nginx Web UI 访问。无需 API 调用、无需数据库写入、无需缓存失效 —— 只是共享文件系统。
这种基于文件的数据传输还有额外优势:天然的持久性和可审计性。每篇博客都是一个独立的 Markdown 文件,文件名带日期时间戳,便于追踪生成历史。(注意,emptyDir 生命周期与 Pod 绑定 —— Pod 重建时数据会丢失。如需持久化,请参见下文“生产建议”。)
Advantage 2: Skill Server 作为 Sidecar
Skill server 是第二个 Sidecar —— 一个轻量级 FastAPI 服务,负责管理 Copilot agent 使用的技能定义。将技能管理拆分为独立容器具有明显优势。
解耦的技能生命周期
技能定义存储在 Kubernetes ConfigMap 中:
apiVersion: v1
kind: ConfigMap
metadata:
name: blog-agent-skill
data:
SKILL.md: |
# Blog Generator Skill Instructions
You are a professional technical evangelist...
## Key Requirements
1. Outline generation
2. Mandatory online research (DeepSearch)
3. Technical evangelist perspective
...
ConfigMap 可以独立于容器镜像更新。当你运行 kubectl apply 更新 ConfigMap 时,Kubernetes 会将变更同步到挂载在 Pod 中的卷。
⚠️ 重要细节:ConfigMap 卷更新不会立即生效。kubelet 通过周期性同步检测 ConfigMap 变化,默认同步周期由 --sync-frequency 控制(默认 1 分钟),再加上 ConfigMap 缓存 TTL。实际传播延迟可能为 1–2 分钟。如果需要立即生效,必须主动调用 /sync 端点触发文件同步:
def sync_skills():
"""Copy skill files from ConfigMap source to the shared volume."""
source = Path(SKILLS_SOURCE_DIR)
dest = Path(SKILLS_SHARED_DIR) / "blog"
dest.mkdir(parents=True, exist_ok=True)
synced = 0
for skill_file in source.iterdir():
if skill_file.is_file():
target = dest / skill_file.name
shutil.copy2(str(skill_file), str(target))
synced += 1
return synced
该设计意味着:更新 AI 行为无需重建镜像或重新部署容器。只需更新 ConfigMap,触发同步,agent 行为即可改变。这对于在生产环境中迭代 prompt 和技能是巨大的运维优势。
💡 进阶思考:为什么不直接将 ConfigMap 挂载到 copilot-agent 的 SKILLS_DIR 路径?虽然技术上可行,但引入 skill-server 作为中间层提供了三重价值:验证、API 访问和可扩展性(见下文“为什么不将技能嵌入 Copilot Agent”)。
最小资源占用
skill server 只做一件事 —— 提供和同步文件。其资源需求如下:
resources:
requests:
cpu: 50m
memory: 64Mi
limits:
cpu: 200m
memory: 256Mi
相比 Copilot agent 的 2Gi 内存限制,skill server 的资源成本微不足道。这正是 Sidecar 模式的优势 —— 可以添加轻量级容器实现辅助功能,而不会显著增加 Pod 总资源消耗。
用于技能内省的 REST API
skill server 提供简单 REST API,使外部系统或运维人员可以查询可用技能:
.get("/skills")
async def list_skills():
"""List all available skills."""
source = Path(SKILLS_SOURCE_DIR)
skills = []
for f in sorted(source.iterdir()):
if f.is_file():
skills.append({
"name": f.stem,
"filename": f.name,
"size": f.stat().st_size,
"url": f"/skill/{f.name}",
})
return {"skills": skills, "total": len(skills)}
@app.get("/skill/{filename}")
async def get_skill(filename: str):
"""Get skill content by filename."""
file_path = Path(SKILLS_SOURCE_DIR) / filename
if not file_path.exists() or not file_path.is_file():
raise HTTPException(status_code=404, detail=f"Skill '{filename}' not found")
return {"filename": filename, "content": file_path.read_text(encoding="utf-8")}
该 API 用途包括:
-
调试:无需 kubectl exec 进入容器即可验证当前加载的技能,大幅降低排障门槛。
-
监控:外部工具可轮询 /skills 确认预期技能集已部署。结合 Prometheus Blackbox Exporter,可实现配置漂移检测。
-
可扩展性:未来系统可通过 API 动态注册或更新技能,为不同 prompt 策略的 A/B 测试提供基础。
为什么不将技能嵌入 Copilot Agent?
将 ConfigMap 直接挂载到 Copilot agent 容器看起来更简单。但拆分为专用 Sidecar 有以下优势:
-
验证层:skill server 可在同步前验证技能文件格式和内容,防止无效技能定义导致 Copilot SDK 运行时错误。
-
API 访问:技能可通过 REST 接口查询和管理,支持运维自动化。
-
逻辑独立演进:如果技能管理变得复杂(例如动态技能注册、版本管理、prompt A/B 测试、基于角色的技能分发),skill server 可独立演进而不影响 Copilot agent。
-
清晰数据流:ConfigMap → skill-server → shared volume → copilot-agent。每个箭头都是显式、可观察的步骤。出现问题时,可以精确定位失败阶段。
💡 架构权衡:对于小规模部署或 PoC(概念验证)工作,直接将 ConfigMap 挂载到 Copilot agent 是完全合理的选择 —— 组件更少,运维开销更低。Sidecar 方法的价值在中大型生产环境中更加明显。架构决策应始终与团队规模、运维成熟度和业务需求相匹配。
End-to-End 工作流
当用户请求生成博客时,完整数据流如下: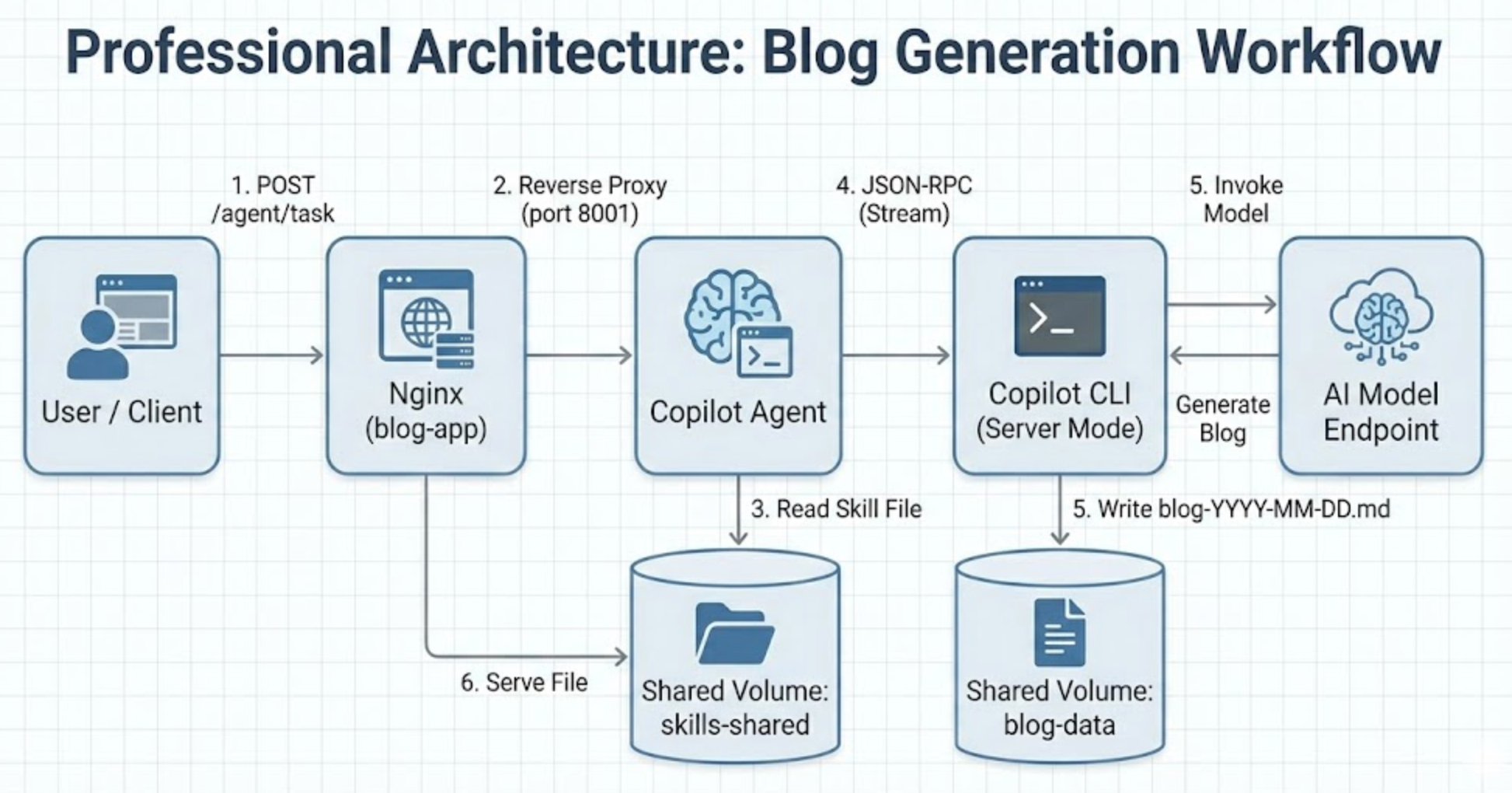
每一步都使用 Pod 内通信 —— localhost HTTP 调用或共享文件系统读取。组件之间无需外部网络调用。唯一的外部依赖是 Copilot SDK 通过 Copilot CLI 连接 GitHub 认证服务和 AI 模型端点。
Kubernetes Service 暴露三个端口用于外部访问:
ports:
- name: http # Nginx UI + reverse proxy
port: 80
nodePort: 30081
- name: agent-api # Direct access to Copilot Agent
port: 8001
nodePort: 30082
- name: skill-api # Direct access to Skill Server
port: 8002
nodePort: 30083
⚠️ 安全警告:在生产环境中,不建议通过 NodePort 直接暴露 agent-api 和 skill-api 端口。这两个 API 应仅通过 Nginx 反向代理路径(/agent/ 和 /skill/)访问,并在 Nginx 层配置认证和限流。直接暴露 Sidecar 端口会绕过反向代理的安全控制。推荐配置:
# Production recommended: only expose the Nginx port
ports:
- name: http
port: 80
targetPort: 80
# Combine with NetworkPolicy to restrict inter-Pod communication
生产建议与架构扩展
将该架构从开发/演示环境迁移到生产环境时,应关注以下方面:
跨平台构建与部署
项目的 Makefile 自动检测主机架构以选择合适的 Docker 构建平台,无需手动配置:
ARCH := $(shell uname -m)
ifeq ($(ARCH),x86_64)
DOCKER_PLATFORM ?= linux/amd64
else ifeq ($(ARCH),aarch64)
DOCKER_PLATFORM ?= linux/arm64
else ifeq ($(ARCH),arm64)
DOCKER_PLATFORM ?= linux/arm64
else
DOCKER_PLATFORM ?= linux/amd64
endif
macOS 和 Linux 均支持作为开发环境,并提供专用工具安装目标:
# macOS (via Homebrew)
make install-tools-macos
# Linux (downloads official binaries to /usr/local/bin)
make install-tools-linux
Linux 安装目标直接从上游发布地址下载 kubectl 和 kind 二进制,并根据架构选择版本,避免依赖除 curl 和 sudo 之外的包管理器。这使得在不同 Linux 发行版(Ubuntu、Debian、Fedora 等)上的环境搭建更加可移植。
健康检查与探针配置
为每个容器配置完整探针,以确保 Kubernetes 正确管理生命周期:
# copilot-agent probe example
livenessProbe:
httpGet:
path: /health
port: 8001
initialDelaySeconds: 10
periodSeconds: 30
timeoutSeconds: 5
readinessProbe:
httpGet:
path: /health
port: 8001
periodSeconds: 10
startupProbe: # AI agent startup may be slow
httpGet:
path: /health
port: 8001
periodSeconds: 5
failureThreshold: 30 # Allow up to 150 seconds for startup
数据持久化
emptyDir 生命周期与 Pod 绑定。如果生成的博客需要在 Pod 重建后仍然存在,可考虑:
-
PersistentVolumeClaim (PVC):将 blog-data 卷替换为 PVC;数据独立于 Pod 生命周期存在
-
对象存储上传:Copilot agent 生成博客后异步上传至 S3/Azure Blob/GCS
-
Git 仓库推送:自动提交并推送生成的 Markdown 文件到 Git 仓库进行版本管理
安全加固
# Set security context for each container
securityContext:
runAsNonRoot: true
runAsUser: 1000
readOnlyRootFilesystem: true # Only write through emptyDir
allowPrivilegeEscalation: false
capabilities:
drop: ["ALL"]
可观测性扩展
Sidecar 模式天然适合添加可观测组件。可以在同一 Pod 中添加第三(或第四)个 Sidecar,用于日志收集、指标导出或分布式追踪: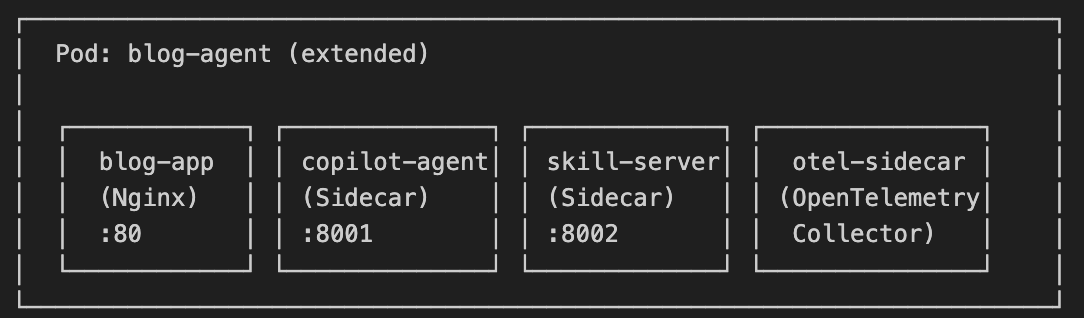
水平扩展策略
由于 Pod 内容器一起扩缩容,HPA 扩缩容粒度为 Pod 级别。这意味着:
-
如果 Copilot agent 是瓶颈,扩展 Pod 副本数也会扩展 Nginx 和 skill-server(由于它们轻量,资源浪费极小)
-
如果未来技能管理变得计算密集,可考虑将 skill-server 从 Sidecar 拆分为独立 Deployment + ClusterIP Service,实现独立扩缩容
从 Sidecar 到微服务的演进路径
双 Sidecar 架构为未来迁移到微服务提供了清晰路径: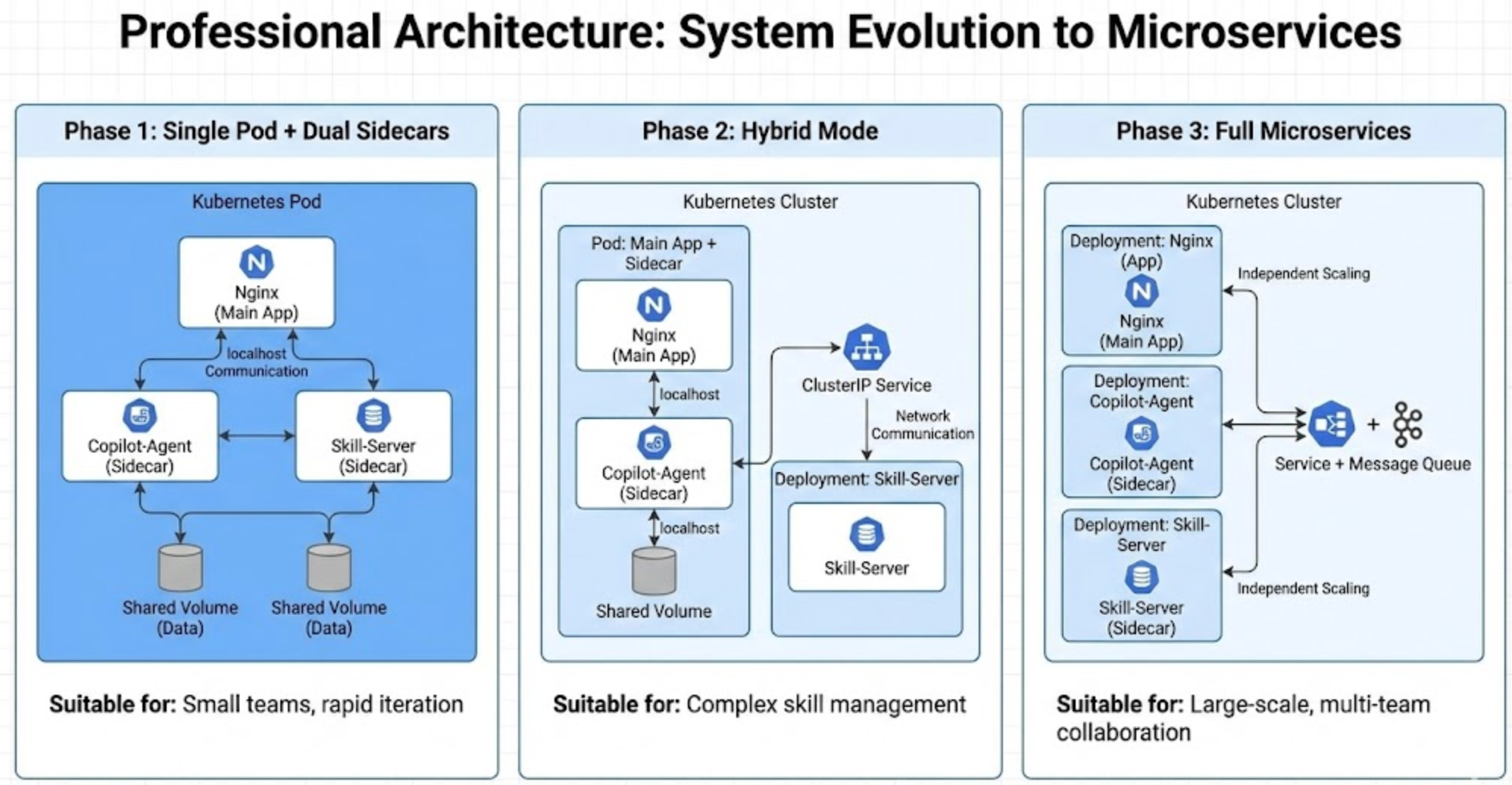
每一步迁移仅需改变通信方式(localhost → Service DNS),业务逻辑保持不变。这正是良好关注点分离所带来的架构灵活性。
总结
本项目中的双 Sidecar 模式展示了一个清晰的云原生 AI 应用架构:
-
主容器(Nginx)保持精简与专注 —— 只负责提供 HTML 和代理请求。它对 AI 或技能一无所知。
-
Sidecar 1(Copilot Agent)封装所有 AI 逻辑。它使用 GitHub Copilot SDK,管理会话并生成内容。它与 Pod 其余部分的唯一耦合点是环境变量和共享卷。容器镜像支持跨平台构建 —— Node.js 通过官方二进制安装并自动检测架构,确保同一 Dockerfile 在 amd64 和 arm64 平台上均可工作。
-
Sidecar 2(Skill Server)为 AI 技能定义提供专用管理层。它在 Kubernetes 原生配置(ConfigMap)与 Copilot SDK 运行时需求之间建立桥梁。
这种分离带来了独立可部署性、隔离的故障域,以及 —— 最重要的 —— 在不重建任何容器镜像的情况下更改 AI 行为(技能、prompt、模型)的能力。
Sidecar 模式不仅仅是架构层面的概念,它是在 Kubernetes 中组合 AI 服务的实用方法,使每个组件能够以自己的节奏演进。随着跨平台构建支持(macOS 和 Linux,amd64 和 arm64)、Kubernetes 原生 Sidecar 在 1.33 版本 GA,以及 GitHub Copilot SDK 等 AI 开发工具的成熟,我们预计这种“AI agent + Sidecar”组合模式将在更多生产环境中得到验证与采用。
参考资料
-
GitHub Copilot SDK Repository — 官方 SDK,支持 Python / TypeScript / Go / .NET
-
KEP-753: Sidecar Containers— Kubernetes 原生 Sidecar 容器提案
-
Kubernetes v1.33 Release: Sidecar Containers GA — Sidecar 容器 GA 公告
-
分布式系统工具包:复合容器模式 — 早期关于 Sidecar 模式的经典 Kubernetes 文章
-
12-Factor App: Config — 外部化配置原则

微软开发者社区,邀请来自微软以及技术社区专家,带来最前沿的技术干货与实践经验。在这里,您将看到深度教程、最佳实践和创新解决方案。
更多推荐



 9
9 0
0- 0



 已为社区贡献33条内容
已为社区贡献33条内容

所有评论(0)